계량투자 실험실 Quantlab
정보이론의 기초
정보이론의 기초적인 문법을 정리한다. 정보의 의미와 엔트로피의 정의, KL 다이버전스 등에 대해 살펴본다. 차후에 다루게 될 머신러닝 관련 포스트에서, 수식전개를 돕기 위해 쓰이게 될 것이다.
정보
정보는 갖고 싶을 만한 가치를 지니고 있어야 한다. 마음만 먹으면 누구라도 가질 수 있거나, 너무 자주 발생해서 쉽게 알아낼 수 있다면, 그건 좋은 정보라고 말할 수 없을 것이다. 혹자는 정보를 놀람의 크기(Surprising degree) 또는 파급력 정도로 이해하기도 한다. 예를들어 내일은 추울수도 있고 더울수도 있다라는 식의 당연한 얘기는, 정보로서의 효용이 크다고 말하기는 힘들다. 하지만 내일부터 장마가 시작된다라는 일기예보는 누가 듣더라도 가치있는 정보가 된다.
정보이론(Information theory)에 따르면 정보량 은 발생확률 의 함수이며, 다음의 4가지 성질을 지니고 있다고 한다.
- 발생확률이 작을 수록 더 많은 정보량을 갖고 있다:
- 정보량은 음이 아니다:
- 반드시 발생하는 사건(deterministic event)의 정보량은 0이다. (즉 정보가치가 없다)
- 독립인 사건들의 정보량은 단순합산(additive)할 수 있다.
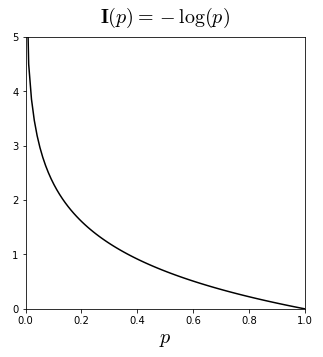
여기서 정보량 는 self-information 또는 surprisal 이라고도 부른다. 섀넌은 위의 성질들을 모두 만족하는 로그함수를 이용하여, 다음과 같이 정보량을 정의하였다.
정보이론에서는 기본 연산단위가 비트(bit)이기 때문에, 주로 이진로그()로 정보량을 정의한다. 이 때의 정보량 단위를 비트(bit) 또는 섀넌(shannon)이라고 한다. 예를들어 발생확률이 25%와 50%인 정보의 정보량을 각각 계산해보면,
즉 발생확률이 낮을 수록 정보량이 더 크다. 참고로 머신러닝에서는 자연로그()로 정보량을 정의하는 경우가 많은데, 가 지수함수 의 역함수일 뿐만 아니라 간편한 미분연산 등 대수적인 전개가 용이하기 때문이다. 이처럼 자연로그를 쓰는 경우의 정보량 단위를 내트(nat) 라고 한다. 정보량의 정의에 의해, 임을 알 수 있다.
엔트로피
엔트로피(Entropy)는 확률변수의 불확실성(Uncertainty)을 측정하는 도구 중의 하나이다. 원래는 고전 열역학에서 소개된 개념인데, 섀넌의 1948년 논문인 A Mathematical Theory of Communication을 통해 정보이론으로 접목되었다. 확률변수 에 대하여, 엔트로피 는 정보량 의 기대값으로 정의된다.
여기서 는 확률변수 의 확률밀도함수를 의미하며, 엔트로피를 의 함수로 이해하는 경우도 있기 때문에, 위의 정의처럼 라고 표기하기도 한다. 한편 엔트로피의 단위는 정보량의 단위에 따라 달라진다. 1
엔트로피는 정보의 불확실성이나, 해당 정보를 접했을 때 느끼는 평균적인 파급력(놀람)의 크기 정도로 해석한다. 왜냐하면 다음과 같은 추론이 가능하기 때문이다.
- 정보량의 기대값이 크면,
- 해당 정보에 대한 평균적인 파급력의 크기가 클 것이고,
- 이느 결과적으로 해당 정보의 불확실성이 크다는 것을 의미한다.
만약 확률변수 가 베르누이 분포 또는 카테고리 분포 등의 이산확률분포를 따른다면, 엔트로피를 좀 더 명시적으로 나타낼 수 있다. 이를 섀넌 엔트로피(Shannon entropy) 또는 정보 엔트로피(Information entropy) 라고 부르기도 한다.2 이산확률변수 의 표본공간(Sample space)3을 라고 하면, 섀넌 엔트로피는 다음과 같다.
이 때 는 확률질량함수가 된다.
Notation이 다소 헷갈릴 수도 있으니 정리하고 넘어가자. 다음의 설정들에 대해서,
- 이산확률변수 의 표본공간
- 의 각 샘플 에 할당된 확률값
아래의 엔트로피 표현들은 모두 같은 의미를 지닌다.
표본공간의 크기가 이라는 것을 표현하기 위해, 각 확률값 의 함수로 나타내는 경우, 과 같이 을 명시적으로 표시하였다.
인 경우
이산확률변수 에서 추출된 어떤 샘플의 발생확률이 일 때에는, 해당 엔트로피의 계산에 이 포함되기 때문에, 엔트로피가 명확히 정의되지 않는다. 이 경우에는 다음을 정의하여 이용한다.
로피탈의 정리(L’Hospital’s rule)에 의해,
이므로, 발생확률이 0인 정보량은 엔트로피 계산에서 제외해도 상관없게 된다. 따라서 발생확률이 0이 아닌 표본공간 에 대해서, 엔트로피는 다음과 같이 계산된다.
예시: 동전 던지기
동전 던지기를 통해 엔트로피의 개념을 이해해보자. 동전 던지기의 확률변수 는 성공확률 의 베르누이 분포를 따른다. 확률질량함수 에 대하여, 자연로그로 정의된 엔트로피를 산출해보면,
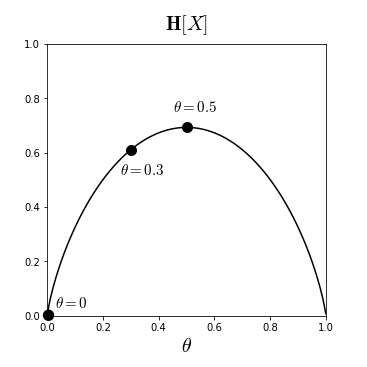
이와 같이, 베르누이 분포의 엔트로피를 성공확률 의 함수로 나타내는 것을 이진 엔트로피 함수 (Binary entropy function) 라고 부른다. 4
- 인 경우:
- 인 경우:
- 인 경우:
따라서 에 가까울 수록 엔트로피가 커진다는 사실을 알 수 있다. 공정(fair)한 동전일 수록 불확실성이 커진다는 것을 의미하는데, 사실 이는 동전 던지기의 확률분포 뿐만이 아니라 다른 모든 확률분포에 대해서도 마찬가지로 적용이 된다. 0과 1 사이의 모든 에 대해서 엔트로피를 그려보면 다음 차트를 얻는다.
주요성질
확률변수 와 가 다음과 같이 정의된 이산확률분포를 따른다고 가정해보자.
Zero probability의 기여
확률이 0인 샘플은 엔트로피에 전혀 영향을 주지 못한다. 으로 정의되기 때문이다. 위에서 [ 인 경우]를 참고.
엔로피의 최대값
이산균등분포 (Discrete uniform distribution)일때 엔트로피가 최대값을 가진다.
Proof. 는 Strictly concave 함수이므로, Jensen 부등식에 의해 다음을 알 수 있다.
여기서 등호는 가 상수일 때, 즉 인 경우에만 발생하므로,
참고로, 연속확률분포의 (연속) 엔트로피가 최대가 되려면, 해당 확률분포가 가우시안 정규분포를 따라야 한다는 사실이 알려져있다. 여기를 참고.
독립분포의 엔트로피 가산성
와 가 서로 독립적인 이산확률분포를 따른다면,
이는, 독립적인 불확실성은 가산된다는 의미로 이해할 수 있다.
Proof.
균등분포의 엔트로피
균등분포의 경우, 표본공간의 크기가 클 수록 (즉 확률변수가 취할 수 있는 값의 수가 많을 수록) 엔트로피가 커진다.
이를테면 동전 던지기 보다 주사위 던지기의 엔트로피가 더 크다고 할 수 있다.
Proof.
결합 엔트로피
결합 엔트로피 (Joint entropy)는 결합확률분포 (Joint probability distribution)의 엔트로피를 말한다. 두 확률변수 의 결합확률변수 에 대한 결합 엔트로피는 다음과 같이 정의된다.
여기서 는 결합확률변수의 임의의 샘플 에 대한 확률밀도함수를 의미한다. 확장하여, 결합확률변수 의 샘플 에 대한 확률밀도함수를 라고 하면,
가 된다. 만약 각 확률변수 가 모두 이산확률분포를 따른다면, 가 취할 수 있는 모든 값에 대하여 다음과 같이 나타낼 수 있다.
교차 엔트로피
하나의 확률변수 를 묘사하는 두 개의 확률분포 와 가 있다고 생각해보자. 현실에서는 이런 경우가 빈번하게 발생한다. 이를테면 확률변수 의 분포를 모르고 있는 상태에서 확률밀도함수를 추정한다면, 해당 확률밀도함수의 추정된 형태는 여러가지가 될 수 있는 것이다. 이럴 때에는 다음과 같이 교차 엔트로피 (Cross entropy) 를 정의할 수 있다.
여기서 는 의 확률밀도함수가 인 경우의 기대값을 의미한다. 로그 안밖의 확률밀도함수가 다르다는 점만 제외하고는, 기존의 엔트로피 정의와 거의 동일하다. 만약 확률변수 가 이산확률분포를 따른다면, 의 표본공간 에 대해 다음과 같이 나타낼 수 있다.
베르누이 분포를 예로 들어보자. 확률변수 의 세 확률분포 , , 에 대한 성공확률 를
라고 한다면,
두 확률분포가 유사할 수록 교차 엔트로피가 작아진다는 사실을 알 수 있다. 베르누이 분포에서 0과 1 사이의 모든 성공확률 , 에 대한 교차 엔트로피를 그려보면 다음 차트를 얻는다. 두 확률분포가 유사한 구간인 부근(점선)에서 교차 엔트로피가 0에 가깝다는 것을 다시한번 확인할 수 있다.
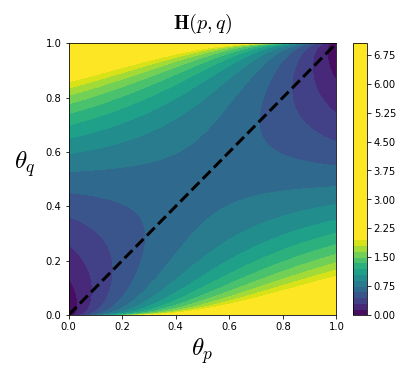
이와 같은 성질 때문에, 교차 엔트로피는 머신러닝의 분류 (Classification) 문제에서 비용함수 (Cost function)으로 쓰이는 경우가 많다. 위의 예를 다시한번 가져와 보자. 를 의 실제 확률분포라고 하고, 해당 확률분포를 추정하여 과 를 얻게 되었다고 하자. 각 성공확률값에 따라 One-hot 인코딩을 통해 클래스를 분류해보면,
여기서 는 One-hot 인코딩 과정을 통해 예상되는 클래스를 의미한다. 가 실제 분포라고 했으므로, 이 확률변수를 분류해보면 class 2가 틀림없을 것이다. 이제, 추정된 분포 과 를 통해 인코딩된 분류를, 교차 엔트로피를 이용하여 검증해보자.
즉, 잘못된 분류를 도출하는 분포의 경우에는 교차 엔트로피가 무한대로 발산하게 된다.
조건부 엔트로피
두 확률변수 가 서로 상관관계가 있을 때, 확률변수 의 실현값 를 조건으로 확률변수 의 엔트로피를 구해보면 가 된다. 이 값의 에 대한 기대값을 조건부 엔트로피 (Conditional entropy) 5라고 하며, 다음과 같이 정의된다.
여기서 은 확률변수 에 대한 기대값을 의미한다. 만약 확률변수 , 가 이산확률분포를 따른다면, 조건부 확률 및 엔트로피의 정의에 의해 다음과 같이 전개할 수 있다.
여기서 , , 는 각각 확률변수 , , 의 확률질량함수를 의미한다. 결합 엔트로피 와 헷갈릴 수 있으므로, 주의하기 바란다.
Chain rule
조건부 엔트로피는 다음과 같은 재미있는 성질이 있는데, 이를 Chain rule 6이라고 부른다.
증명해보자.
여기서
임을 이용하면 증명이 완성된다. Chain rule을 활용하면 다음을 추가적으로 알 수 있다.
엔트로피 Chain rule의 일반형
Chain rule을 보다 일반적으로 기술하면 다음과 같다.
증명은 간단하다. 다음 식들을 모두 합산해보면 위의 식을 얻게 된다.
정보이득
정보이득(Information Gain)은 주어진 정보로 인해 확률변수의 불확실성이 얼마나 감소했는지를 나타내는 지표이다. 정보이득 는 다음과 같이 정의된다.
KL 다이버전스
KL 다이버전스 (KLD: Kullback–Leibler divergence, 쿨백-라이블러 발산)는 하나의 확률변수에 대한 두 확률분포 간의 차이를 측정하는 도구 중 하나이며, 상대 엔트로피(Relative entropy) 라고도 한다. 확률분포 와 에 대하여, 다음과 같이 엔트로피와 교차 엔트로피 간의 차이로 정의된다.
수학적인 의미는, 어떤 확률분포 가 있을 때, 그 분포를 근사적으로 추정한 확률분포 를 대신 사용했을 경우의 엔트로피 변화를 말한다. 엔트로피와 교차 엔트로피의 정의에 의해,
임을 알 수 있다. 만약 가 이산확률변수이고, 표본공간 에 대하여 및 이라면, 가장 널리 알려진 다음의 정의를 얻게 된다.
한편, KL 다이버전스를 두 확률분포 간의 거리 개념으로 이해할 수도 있다. 단 Symmetric 하지는 않다는 점을 명심해야 한다. 즉,
Information inequality
의 두 확률밀도함수 에 대해서, 다음의 부등식을 Information inequality 라고 한다.
Information inequality를 이용하면, KL 다이버전스의 정의에 의해 다음의 부등식을 추가적으로 알게 된다.
Proof. 는 Strictly concave 함수이므로, Jensen 부등식을 이용하면,
여기서는 가 이산확률변수라고 가정하였는데, 연속확률변수인 경우에도 같은 논리를 적용할 수 있다. 이를테면 이므로, 결국 위와 동일한 부등식을 얻을 수 있게 된다.
한편 등호는 가 상수일 때 성립한다. 에서
따라서 모든 값에 대하여 가 된다.
다음 차트는 다양한 위치의 두 정규분포에 대하여 KL 다이버전스를 측정해 본 결과이다.

예시
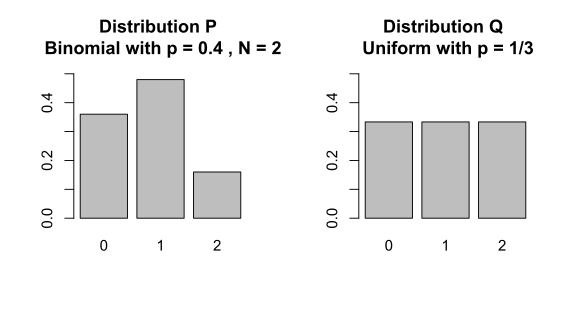
아래 표에서 는 이항분포(Binomial distribution), 는 균등분포(Uniform distribution)을 나타낸다.
| 1 | 2 | 3 | |
|---|---|---|---|
| 0.36 | 0.48 | 0.16 | |
| 0.333 | 0.333 | 0.333 |
-
만약 정보량의 단위가 비트라면(즉 정보량을 이진로그로 정의한다면) 엔트로피의 단위도 비트가 된다. 반대로 정보량의 단위가 내트라면(즉 정보량을 자연로그로 정의한다면) 엔트로피의 단위 역시 내트가 된다. ↩
-
이와는 반대 개념으로, 연속확률변수에 대한 엔트로피를 연속 엔트로피(Continuous entropy or Differential entropy) 라고 하며, 다음과 같이 정의된다. ↩
-
보통은 이진로그로 정의하는 경우가 많으나, 여기에서는 자연로그를 썼다. ↩
-
조건부 불확실성 또는 Equivocation 라고도 부른다. ↩